Let’s say you’re writing a function that takes user input and checks if it matches some secret.
You’ll be exposing this checkSecret function to external users so you want to make sure it’s safe to use without leaking the secret. As long as your secret is long enough, it’s unlikely to be brute-forced. You’re feeling pretty confident that this simple function that does nothing but check equality doesn’t have any glaring security flaws.
Anyway, an adversary who can call this function repeatedly can derive a 10-character secret in just a few thousand calls to checkSecret.
How?
Builtins checking equality are implemented in native code that may differ per runtime, but it’s straightforward to imagine how anybody would implement it. === has some details regarding string interning that make analysis a lot more complicated, so we’ll use startsWith for this post. Ignoring details, startsWith might look something like this:
Just iterate through the input and check if the character at each position matches. If not, break early and return false. If so, return true. While the spec doesn’t technically require early exit, most implementations use something like the above. (See V8’s implementation here.)
Break early is the important part. On average, guesses whose prefixes partially match the secret’s are going to take a bit longer to return than guesses that are totally wrong, and the longer the prefix match, the longer the function is going to take. We can measure this directly in your browser:
Running startsWith a few thousand times...
If your browser supports accurate-ish timers, you’ll see that the distributions overlap but the blue plot is shifted to the right, because, on average over many calls, "password".startsWith("pxxxxxxx"); takes longer than "password".startsWith("xxxxxxxx");.
We can use this characteristic to guess the secret by timing lots of calls to checkSecret. Using information like time or memory usage is known as a side-channel attack.
Let’s see if we can run a timing attack on this page! This is a toy example, but the ideas apply to real-world systems.
Demo
I’m not paying for a server for this post; Cloudflare1 is kindly hosting this site for free. Instead, we’re going to simulate the server by running the checkSecret function in a web worker. This is a separate thread that can’t access the DOM but is still running in your browser. We’ll measure the time it takes to run checkSecret and use that to guess the secret2.
We need to check a few things before we can run the demo. First, let’s make sure that your browser supports web workers:
Checking for web worker support...
We also need to ensure that it supports cross-origin isolation. Browser timers are coarsened to 100μs precision unless isolated
to prevent attacks just like this. It’ll still work with the imprecise timers, but the demo will take much (much) longer.
Testing cross-origin isolation...
Note that this example is fastest on desktop Chrome and Chromium-based browsers, which support 5μs precision, matching the spec. Firefox, Safari, and mobile WebKit-based browsers are stuck at 20μs because they were scared off by Spectre in 2018 and haven’t come up with a better solution yet.
Since the browser is rudely not giving us the time resolution we need3, we need to repeat each trial enough times to
actually register on the clock. Below, we’re running a benchmark to see how many times we need to call checkSecret in order to spread the result across a couple of buckets. Otherwise, all times will be 0 and it’ll be hard to do any statistics.
Benchmarking page to choose good parameters...
Running this outside a browser context or anywhere with more precise timings, you could stick with a much smaller number of iterations.
Let’s guess your password! Enter a lowercase 8-character password below (I promise the web worker isn’t cheating, but this post comes with source maps so you can check for yourself):
How’d we do? There are ~209 billion 8-character lowercase passwords. We guessed yours in
not guessed yet...
guesses. Since this approach scales linearly(ish) with the length of the password, rather than exponentially, longer passwords aren’t enough to mitigate the issue.
Optimizing the guessing technique
What is the guesser above actually doing? The obvious attack approach here is to try to derive one character at a time in the prefix. Make lots of guesses, measuring the time per-prefix. Once it’s clear that one consistently takes longer than the others, fix it and repeat with the next character.
The problem with this approach is that computers are noisy and – especially over a network boundary or with limited timing capabilities, it might take a lot of samples to come to that clarity. We want to minimize the number of guesses we expect to need to make so this attack is feasible in a reasonably short amount of time.
First, let’s formalize the problem a bit. Assume for simplicity that the secret length \(l\) and the permissible character set \(C\) are fixed4. We have a list of zero or more (guess, time(checkSecretNTimes(guess))) measurements that we’ve already taken that we’ll call \(M\). We want to land on some strategy \(makeGuess(l, C, M) \rightarrow guess\) that emits guesses that yield the most expected additional information.
Thompson Sampling
A simple but effective approach is Thompson Sampling. If we build up our guesses one character at a time, we can reframe this problem similar to a stochastic multi-armed bandit problem – at each step, we have a set of possible arms (characters by which we could extend the prefix) and we want to pick the best one to make the most effective guess.
Since we have the list of measurements \(M\), we can always estimate the distribution \(D_{\text{prefix}}\) by filtering to all of the data that begins with that prefix and updating our prior distributions given that data. Thompson Sampling is simply sampling a single value from each distribution \(D_{\text{prefix} + c}\) for \(c \in C\) and choosing the \(c\) with the largest value. In pseudocode, \(makeGuess(l, C, M)\) looks like:
Set prefix to the empty string
While length(prefix) \(< l\):
Set bestSample to \(-\infty\) and bestGuess to nil
For each character \(c\) in \(C\):
Fit a distribution \(D_{\text{prefix} + c}\) to \(M\)
Take a single sample from \(D_{\text{prefix} + c}\)
If the sample is greater than bestSample, set bestSample to the sample and bestGuess to \(c\)
Set the prefix to prefix + bestGuess
Return prefix
Intuitively, this means that the more confident we are in a prefix, the more likely it is that we’ll choose it, and the more data
we have the more we can build our confidence levels to make our next guess even better.
But what does “fit a distribution” mean?
We have no idea what the distribution of time(checkSecret(guess)) might be. Luckily, due to the Central Limit Theorem, we can assume5 that samples from time(checkSecretNTimes(guess)) are approximately normal with mean \(N \cdot \mu\) as long as N is sufficiently large. Because of the timing constraints outlined above, we need to repeat our guesses many times anyway, so our samples are going to look approximately normal no matter what the real distribution of time(checkSecret) on your computer might be.
Assuming normality is especially convenient because the algorithm described above would be devastatingly slow if we had to iterate through all of \(M\) every time we wanted to estimate some distribution’s parameters. Instead, we can just keep track of the sample mean and variance of each distribution and update them as we go. We’re going to make a lot of guesses, so we need online updates to make guesses in \(O(l * \vert C\vert)\) time rather than \(O(\vert M\vert)\). We can use the Welford algorithm to update the mean and variance of each distribution in constant time as we gather more samples.
Storing lots of distributions
To make a guess, we need to quickly sample from the normal distributions that we’re storing per-prefix. We can use a Trie where each node stores the parameters of the normal distribution that we believe describes the prefix defined by that node and where the edges are the elements of \(C\). This way, we can quickly update the mean and variance of each distribution and quickly sample from them.
Whenever we get a new measurement, we can update the mean and variance of each node on the path as we walk the trie.
Example: updating the trie
As we take measurements, we can quickly update the trie to reflect our new data.
Expand to see example.
First, we guess `abc` and measure time `(0.4)`. We update the trie:
Updating the trie takes only \(O(l)\) time, because we only have to update the mean and variance of the nodes on the path to the leaf, and each online update is constant time.
If \(M\) is large, we might have a lot of nodes in the trie. We could prune the trie by removing nodes that have too few measurements – however, in practice, we can usually just keep the whole trie in memory since the search usually completes within a few thousand guesses.
Sampling from the trie
We walk the trie, taking a sample from each node’s distribution, and choose the character that leads to the largest sample. However, we may not have samples from all nodes, so with some probability we choose a random character to ensure we continue to explore the space so we don’t get stuck.
Our guessing algorithm is similar to that described above but takes two important parameters:
NOISE_PER_STEP: the probability that we choose a uniformly random character out of \(C\) instead of sampling from the trie.
MIN_SAMPLES: the minimum number of samples we need to have from a node before we consider it. With only a few samples, the parameters of the normal distribution are not very reliable and we’re likely to make a bad guess. There are more sophisticated statistical techniques to express certainty here, but just not considering nodes with count < 3 works fine in practice. This way, we don’t need to build a robust prior distribution instead just ignore any prefixes with too few measurements until they have > MIN_SAMPLES measurements in \(M\).
So, extending the algorithm from above, we update \(makeGuess(l, C, M)\) to:
Set the prefix to the empty string
While length(prefix) \(< l\):
Look up the prefix in the trie
If the prefix isn’t in the trie, return the prefix + random characters up to length \(l\)
Set bestSample to \(-\infty\) and bestGuess to nil
For each character \(c\) that are children of the current node and have count > MIN_SAMPLES:
Look up the distribution \(D_{\text{prefix} + c}\) in the trie
Take a single sample from \(D_{\text{prefix} + c}\) using the Box-Muller transform
If the sample is greater than bestSample, set bestSample to the sample and bestGuess to \(c\)
Set the prefix to prefix + bestGuess
Return the prefix
We repeat this many times, adding the (guess, time) data to the trie describing \(M\) to inform our guesses, until hopefully we guess the right secret.
Using this approach over the network
There may be situations in which you’re trying to exfiltrate a secret locally – however, the majority of the time you’ll be trying to guess a secret over a network boundary. In this case, you’ll need to take into account the noise of the network.
This is a bit trickier because the network noise is probably greater than the time it takes to run checkPassword, and other traffic may impact timing information, so each measurement is generally going to yield a lot less information than the relatively direct measurements we’re taking here. However, if you’re allowed enough trials, the same approach works with no code changes, since we didn’t make any assumptions about the underlying distribution and the network jitter just increases the mean and variance of the distributions that we’re measuring.
Running this algorithm against a much noisier distribution is much slower so isn’t as conducive to an inline demo but if there’s interest, I may host an endpoint with a vulnerable checkSecret to see who can break it first!
Finally
When you’re writing software that compares user-provided data against sensitive values:
Don’t. You should almost never be comparing directly against secret values. Use hashes, pdkf2, or whatever is appropriate for your situation. But even these algorithms may perform differently with different inputs, so be careful!
If you must use a secret value as a function input, do so very carefully! Network noise doesn’t necessarily save you. Use a vetted library that does sensitive operations for you instead of trying to implement it yourself, and always ensure solid rate limits are in place.
While I used startsWith in this post, almost any non-constant-time comparison is susceptible to the same attack. Even the === operator is likely to be vulnerable given enough trials if you’re careful about avoiding string interning that leads to constant-time comparison (I couldn’t get this working, but I’d be curious to see if anyone can.)
Footnotes
I had to move this damn site from Github Pages to Cloudflare because Github Pages doesn’t support custom headers, which are needed for cross-origin isolation. Cloudflare has been great so far but I refuse to be trapped into blogging about setting up a blog. ↩
To make the demo run snappily, we aren’t sending messages back and forth between the web worker and the main thread. Instead, we’re just running the checkSecret function in the web worker and measuring the time it takes to run. This is a bit of a cheat, but the same code would work to guess secrets over an actual noisy network boundary – it might just take a bunch more guesses. ↩
I originally wrote this code in Node and was flummoxed when all timings were exactly 0.0000000000000ms when running code in the browser that I knew took at least 30 or 40 μs in Node. ↩
In the real world, you will often know the length of the secret (e.g. an API key) but even if you don’t, this same technique works – just run the same algorithm repeatedly, fixing the length each time. Similarly, in the real world, “printable ascii characters” is usually a pretty good bet for an allowable character set. ↩
Assuming these measurements are independent – which they might not be, since they’re taken back-to-back on a machine, but close enough. ↩
In April, the American College of Radiology released a statement . . . expressing concern that scans could lead to “nonspecific findings” that require extensive, expensive follow-up.
In fact, that isn’t quite what the American College of Radiology said. Their statement didn’t use the word require, but instead expressed concern that scans could lead to nonspecific findings that result in extensive, expensive follow-up.
The require vs result in mixup seems like a semantic point but it’s an important one. The ACR is not saying that follow-ups are necessary, only that they are common. These often spurious, dangerous, and expensive follow-ups are a symptom of broken processes in healthcare, not a predetermined consequence of an untargeted MRI.
More data is better
“If you scan more, you see more” is certainly true. But “if you see more, you do dangerous invasive follow-ups” doesn’t have to be. Unless we change the culture from “if you see something incidental, you must act” to “if you see something incidental, you must act if the disease is likelier to harm2 you than the follow-up,” we’ll be stuck fearing incidental findings forever.
As a bonus, by gathering more data about you, we can regularly update our priors about whether each disease is likely to cause harm.
There’s no Platonic ideal of a human body. Instead of comparing your body to some ideal from which it will always deviate, we should be comparing it
against your baseline. If you see something suspicious – but it hasn’t changed from your last scan – it’s likely not suspicious after all. If we do it right, more scanning should decrease the number of false positives, not increase them – but only if we’re good about not panicking when we see something outside of the “normal” range the first time we measure it3.
Philosophical point taken, but if I test positive for something, I’m still going to get the follow-up!
I’m certainly not arguing that everyone should get all of the tests all of the time (yet). They cost money and resources,
and because medicine is so intervention-focused today, if you get a test, your doctors may very well feel compelled to act on it – if only to protect themselves from a lawsuit4.
But we should be working to change that. We should be working to make each piece of data as cheap and safe5 as possible to gather,
and we should measure baselines to rule out items of concern that haven’t changed from exam to exam. We should be working to make healthcare more data-driven and less likely to skip straight to dangerous interventions. We should also be working to stop treating every piece of data as a binary “positive” or “negative” result and avoid punishing doctors for making the right statistical decisions.
Nikhil Krishnan has a great piece on why we don’t screen healthy people to catch diseases early. Cribbing directly from that piece (which is worth a read), let’s consider the extreme example of Nikhilitis, a disease that affects 1/1000 people. We have a cheap screen that is safe and 99% sensitive (if you have it, the test will be positive 99% of the time) and 90% specific (if you don’t have it, the test will be negative 90% of the time).
This means that if a random member of the population tests positive, they have a 1% chance of having Nikhilitis (math in footnote6). Subsequent health decisions should be based on that number, not on the scary word “positive.”
Let’s also imagine that the confirmatory diagnosis is a lobotomy with a 0.1% mortality rate. If the expected mortality rate of Nikhilitis is less than 10%, don’t get the freaking lobotomy! (The same footnote6 goes on to explain your expected mortality rate via confirmatory biopsy vs Nikhilitis.) But, if you’re in a special population where Nikhilitis is especially dangerous, the lobotomy might be the right choice.
Even Nikhil, whose post is otherwise excellent, implies that everyone who tests positive needs a biopsy. They don’t need a biopsy. The screen cannot ever tell you directly whether or not to get a biopsy; it just gives you more information about your risk for Nikhilitis. You only need a biopsy if that new information (plus other information about you) indicates that you’re safer to get the lobotomy than to let the possibility of Nikhilitis ride.
So if no one should get the follow-up, what was the point of the screen anyway?
Unlike the Nikhilitis screen, baseline measurements like blood panels or full-body MRIs have utility outside of a binary decision on a specific day. If you get a full-body MRI, you have information that is affirmatively useful for your healthcare down the line. How useful will depend on how many people get these MRIs and the quality of science we can do with the data. It’s a tricky cold-start problem but, in my view, it’s the most important one that we have to solve to stop people dying of preventable diseases.
But we live in the real world, where people don’t understand conditional probability and will get the follow-up anyway
A few (untested) suggestions that I think might marginally improve how we discuss preventative healthcare:
Report screening results as percentages rather than “positive” or “negative”
If your screen comes back positive for Nikhilitis with no other indicators, the report (and your doctor) should explain that “our data tells us that you have about a 1% chance of having Nikhilitis given everything else we know about you.” The words “positive,” “reactive,” “abnormal,” and similar should be reserved for extremely significant results. Doctors have trouble understanding this too, so the labs themselves should be careful about the language in their reports.
Stop calling full-body MRI a “screen”
We shouldn’t be thinking of full-body MRI as a “screen.” Instead, it’s just a series of measurements. In the same way that most of a normal panel of blood tests are not a “screen” so much as they are individual measurements of your cholesterol, your liver function, and so on, a full-body MRI is just a series of measurements of your body’s structure and function. While many companies in the space are marketing themselves as screeners, the responsible ones are quietly figuring out how to gather repeatable data as cheaply and easily as a blood test.
Unless you’re using an MRI to screen for specific diseases (in which case you should be giving careful Bayesian treatment as above) we should be using these technologies to gather baselines and understand change, rather than treating them as solely point-in-time mechanisms to catch specific diseases early.
Longitudinal data is useful
We should track changes over time. If something is stable, it’s probably not a problem. If something is changing, it might be. For example, I have a cyst in my pelvis. It hasn’t changed in years. In 20 years, when I’m getting an MRI for one reason or another, the doctor will likely want to do something about the cyst. But I will know that the cyst has been there, perfectly safe and unchanging, for decades. That information about one of many little ways I’m a bit abnormal may prevent me from going under the knife.
Incentive alignment is hard, so we have to keep driving costs down
What’s the incentive for you to get tests if they’re not immediately actionable? It’s hard to justify spending a big chunk of money (or a big chunk of shared healthcare bandwidth) on something with no immediate payoff. If the Nikhilitis test doesn’t give you any actionable insight, what was the point? As costs decrease and science improves, the value per datapoint gathered will increase while the cost to gather each datapoint will decrease until eventually the lines cross. To get to that point, we need to subsidize the cost of gathering data and make it as easy as possible to gather across healthy and unhealthy populations.
Finally
Don’t be afraid to get the full-body MRI – but before you look at the results, be prepared to (maybe) ignore (only maybe) scary findings. Remember, without the test, you wouldn’t have found out about these findings anyway! Armed with new information, you can track if there is change over time; and if there’s something obvious and immediately actionable, you’ve caught it early.
We should be encouraging data gathering at scale. The alternative – keeping our heads in the sand – will keep us dying in
the dark as people continue to suffer from diseases we would have caught early if we’d been brave enough to look.
Thanks to Ben Weems and Elisabeth Ostrow for their feedback on this post!
I used to run the software engineering team at Q Bio, a company that works on full-body MRI. We didn’t think of our scans as screening for specific diseases so much as a way to gather a ton of data about a person’s health over time, and to use that data to make that person’s healthcare better. That said, it’s always hard to gather data about a person and tell them “don’t do anything about it!” ↩
Including financially, emotionally, or however else you define harm. ↩
It isn’t currently permissible within our ethical framework, but imagine a situation where everything about you got measured every year from, say, 18-35 and kept hidden from you and all of your doctors for the first 15 years. Think of all the useful data you would have when you got knee pain at 35! “Oh, this cyst in my knee has been here the whole time; it’s probably not that.” ↩
Malpractice law is not set up for this kind of thinking. I don’t have an easy solution for this. ↩
Note also that, unlike a CT scan, MRI is near-100% safe (modulo getting accidentally smashed by an oxygen canister that somebody accidentally brings into the room,) so \(P(\text{test harms you})\) is near 0. So, we should be giving people MRIs regularly, (if they’re cheap enough), and updating our priors about our health with the information they provide. Just don’t do a biopsy or an X-ray unless those priors are high enough! ↩
First, let’s calculate the probability that you have Nikhilitis given a positive test. We know that:
Now, if the baseline mortality rate of Nikhilitis is 1% and assuming that the test sensitivity is independent from the mortality rate, if you have a positive test, your posterior probability of dying from Nikhilitis is 1% (chance of having it) * 1% (its mortality rate) = 0.01%. If the mortality rate of the confirmatory diagnosis or other follow-ups are themselves greater than 0.01%, (or otherwise have financial/psychological/quality-of-life harm equivalent to that risk) you shouldn’t follow up.
Concretely, in our example, the confirmatory test has a 0.1% mortality rate. You shouldn’t get the confirmatory test, since 0.1% > 0.01%! If you’re in a population where Nikhilitis is >10% fatal, though, you probably should – because all of a sudden, your chance of dying from Nikhilitis is at least 1% * 10% = 0.1%, so the lobotomy is at least as safe as chancing Nikhilitis.
Disclaimers abound here, of course. Mortality is not the only danger, money is not the only cost, and these numbers are extreme. But the reasoning holds even if the real-world calculations need more terms. ↩↩2
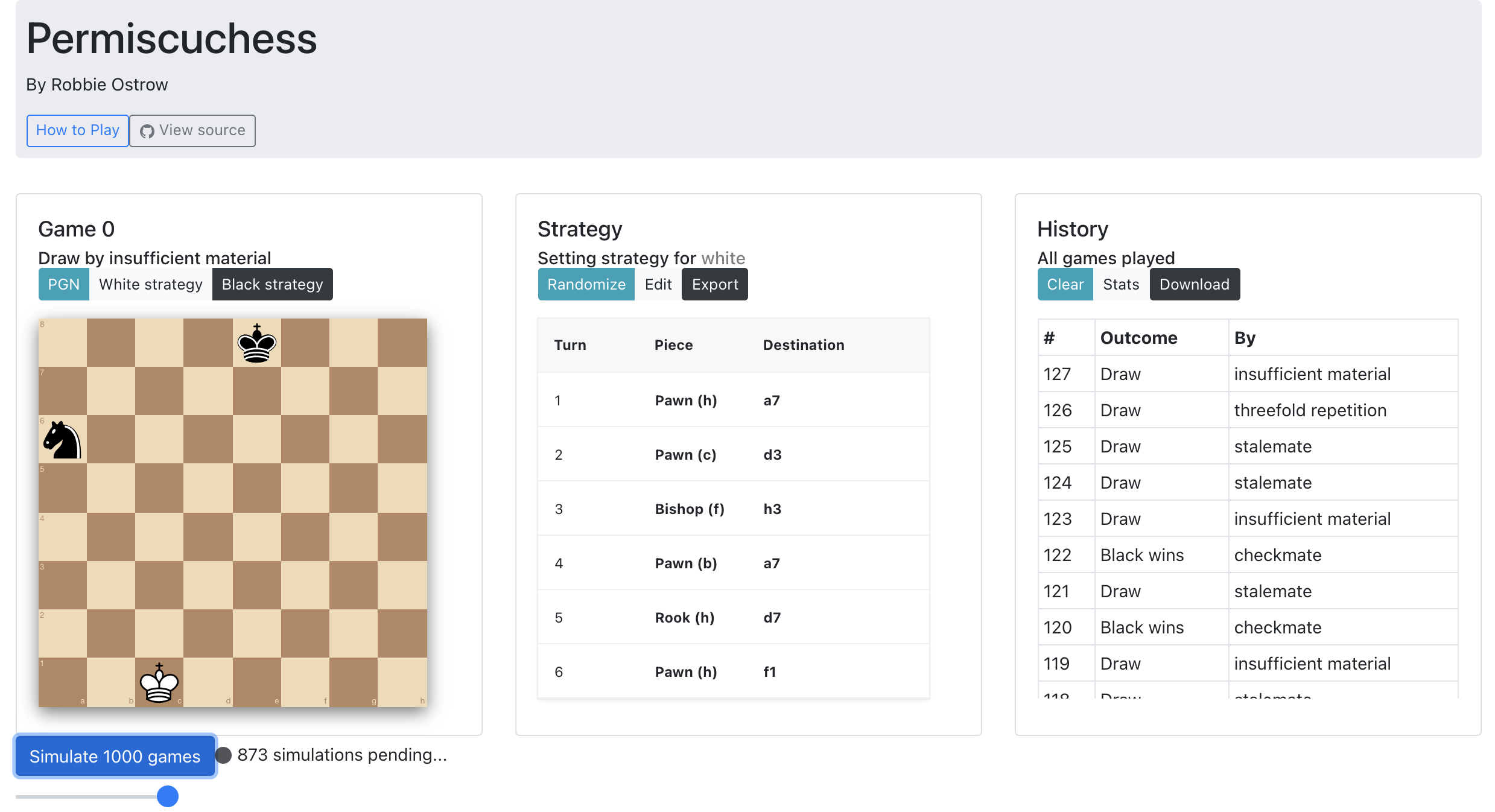
]]>Robbie Ostrowrobbie@ostro.wsPermiscuchess2021-03-16T00:00:00+00:002021-03-16T00:00:00+00:00/permiscuchessChess for people who are good at computers and bad at chess.
Many of my colleagues are excellent chess players. I am not. Something had to be done.
Enter a new chess variant: Permiscuchess! Permiscuchess is a chess variant that is entirely pre-played. Instead of a real-time battle of wits, Permiscuchess is played by devising a clever strategy – a permutation of all chess moves, to be applied one at a time until you win, lose, or draw against thousands of random adversaries.
Play Permiscuchess here. All simulations are done client-side and there is no leaderboard. But feel free to email me to gloat if you find a really good strategy, or send me a Lichess link to a funny game1.
It doesn’t work very well on phones.
I won’t get into all of the rules here – click on “How to play!”
Going for scholar’s mate as white (pe:e4, bf:c4, q:f3, q:f7, then random) wins about 35% of the time. Can you do better?
Open a game in Lichess by selecting the game, clicking “PGN,” and clicking “Open in Lichess.” ↩
]]>Robbie Ostrowrobbie@ostro.wsImproving Type Safety with ts-json-validator2020-02-15T00:00:00+00:002020-02-15T00:00:00+00:00/ts-json-validatorLet JSON play nicely with Typescript using ts-json-validator.
Why?
Naturally, all of the code you write is typed perfectly. But you’re not in charge of all that pesky data that
comes from other places.
JSON.parse returns type any, which mangles all of your hard-earned strictness.
JSON validators are great, but they usually require you to define two things: the validation function and the
Typescript type to go along with it. These can get out of sync and are generally a pain to maintain. JSON schema is a terrific idea, but the schemas are often tricky to write and even trickier to understand.
ts-json-validator allows you to define everything in one place. It generates a compliant JSON schema, a Typescript type that matches objects that can be parsed by that schema, and provides a typesafe parse that throws if the JSON you get doesn’t match the type you’re expecting.
See the readme or install from npm if you don’t care about how the library works and just want to use it.
How?
]]>Robbie Ostrowrobbie@ostro.wsTaking Types Too Far2019-12-09T00:00:00+00:002019-12-09T00:00:00+00:00/taking-types-too-farHerein we check the Collatz conjecture using only Typescript’s type system.
I love Typescript, but it isn’t nearly ambitious enough. It would be vastly improved with an --extremelyStrict flag enforcing that your Typescript code is free of side-effects; that is – no Javascript code is generated at all. Real programmers do all of their computation within the type system. Otherwise, they can’t be sure their program will work in production and should be duly fired.
“But you can’t even do arithmetic in the type system,” you complain. Not so.
Javascript is all well and good, but nobody really knows how the integers are defined. If we’re going to do Real Number Theory, we need to be sure that our numbers are formal enough to pass muster. Trust your own logic, not the Ecma committee’s. Javascript doesn’t have a natural number type, and you never know what might happen when you try to use Javascript numbers when you’re trying to do Precise Mathematics.
So let’s define the natural numbers.
Here we are:
typeNatural={prev:Natural};
Easy. We have a type that we’ve called Natural. It’s not a natural number yet, though. Let’s see if we can get it to comply with the Peano axioms, which is a set of axioms that formalizes the properties of these natural numbers.
It’s not that useful to have a set of natural numbers that doesn’t do anything. We need a way to transform one into another – a successor function S will do the trick:
typeS<TextendsNatural>={prev:T};
Let’s check the first Peano axiom – namely, Zero is a natural number:
typeisZeroANaturalNumber=ZeroextendsNatural?true:false;// type isZeroANaturalNumber = true
Nice. You can check the rest on your own time.
Let’s write out the first few numbers:
typeOne=S<Zero>;// type One = { prev: Zero }typeTwo=S<One>;typeThree=S<Two>;typeFour=S<Three>;typeFive=S<Four>;typeSix=S<Five>;// type Six = { prev: S<S<S<S<S<Zero>>>>> }typeSeven=S<Six>;typeEight=S<Seven>;typeNine=S<Eight>;// ... and so on
Sweet! We’ve defined the natural numbers. Everything else is just notation.
Following along? Here is a Typescript playground with what we’ve done so far.
This seems like a good time to introduce the Collatz conjecture. Unproven until today (and after today, despite my best efforts,) it states:
Take any natural number. If it’s even, divide it by two. If it’s odd, multiply it by three and add one. Repeat. Eventually, you’ll end up at one.
Or, more formally:
\[\begin{equation*}
f(n) =
\begin{cases}
n/2 &\text{n is even}\\
3n+1 &\text{n is odd}
\end{cases}
\end{equation*}\]
Apply f enough times to any natural number, and the Collatz conjecture conjects that you’ll eventually end up at \(1\).
To check Collatz using our fancy new Natural type, we need to define division by two, multiplication by three, and addition by one. To be safe, let’s just define addition, subtraction, multiplication, and division.
First, let’s define a predecessor function P, which is the opposite of our successor function S. P<Zero> doesn’t make sense, so it is of type never.
typeP<TextendsNatural>={prev:T["prev"]["prev"]};
Addition is very straightforward. We can define it recursively as
It might be clearer to write type Add<A extends Natural, B extends Natural> = B extends Zero ? A : S<Add<A, P<B>> but we need to use this indexing hack to get around Typescript’s limitations on circular references in types.
Subtraction isn’t too hard either:
\[A - 0 = A\]
\[0 - S(B) = never\]
\[S(A) - S(B) = A - B\]
Intuitively,
Zero is also the subtractive(?) identity
Zero minus a positive number is undefined (natural numbers start at zero!)
Division is the trickiest of the bunch, but still not too bad.
Since we’re only dealing with the natural numbers, we can assign never to types that represent division of a number by a non-factor.
\[A / 0 = never\]
\[0 / S(B) = 0\]
\[S(A) / S(B) = S((A - B)/S(B))\]
Intuitively,
Anything divided by zero is undefined
Zero divided by a positive number is zero
Each time we can subtract B from A, we add one to the result; that is: \((A + 1) / (B + 1) = ((A + 1) - (B + 1)) / (B + 1) + 1 = (A - B) / (B + 1) + 1\)
Since we’re really abusing the type system, if we want to write division like this without any warnings, we need to use a Typescript branch like this one that allows for deeper instantiated types, since we’re generating types that quickly exceed the default depth of 50.
Finally, it’s time we actually check the Collatz conjecture. We need one more utility, to check if a number is even.
We could do this using our Divide type but it’s a bit unwieldy. Instead, we can define even numbers using the following recurrence:
typeCollatz<TextendsNatural>={0:true,1:Collatz<Even<T>extendstrue?Divide<T,Two>:// If even, divide by twoS<Multiply<T,Three>>// Otherwise, multiply by 3 and add 1}[Equals<T,One>extendstrue?0:1]// One? True, otherwise Collatz<T>
To be fair, we can only check Collatz chains that are very short. Without configuring Typescript’s maxInstantiationDepth, we get lots of Type instantiation is excessively deep and possibly infinite errors when we check massive numbers like three.
But we don’t bother ourselves with silly details like reality; after all, if we had infinite memory we’d have a perfectly good Turing machine. We could optimize our types to be less greedy about using levels we don’t need, but that’s not really the point here.
typec1=Collatz<One>;// true (1)typec2=Collatz<Two>;// true (2 -> 1)typec3=Collatz<Three>;// Error: Type instantiation is excessively deep and possibly infinite. (True if we configure the depth to be larger; (3 -> 10 -> 5 -> 16 -> 8 -> 4 -> 2 -> 1))typec4=Collatz<Four>;// true (4 -> 2 -> 1)typec8=Collatz<Eight>;// true (8 -> 4 -> 2 -> 1)
Here’s a typescript playground with all of the code in this post. You can use the primitives here to do other cool stuff – how about a primality checker?
Armed with tools to do arbitrary computation within the Typescript type system – go forth and make your teammates dread reviewing your code! Godspeed.
See my library, ts-json-validator if you want to use the flexibility of the type system for actual good, or this Github issue for some more fun around the Turing-completeness of the type system.
]]>Robbie Ostrowrobbie@ostro.wsTINE-CNN Augmentation2018-08-01T00:00:00+00:002018-08-01T00:00:00+00:00/tine-cnnTINE-CNN Augmentation (pronounced Tiny-CNN Augmentation) is a new way to perform automatic data augmentation for any image classification task.
Neural networks need a great deal of data on which to train. On many tasks, this problem is partially mitigated by data augmentation and transfer learning. However, it’s not always clear what type of data augmentation is reasonable for a specialized dataset – for example, adding rotation into MNIST will result in confusing 6 and 9. In addition, deciding how to effectively augment a training dataset adds yet more hyperparameters to an already large model-design decision space. Augmentation is typically an ad-hoc process, and although there is recent work attempting to integrate it more naturally into the training process, there is no generic framework that researchers tend to use. Even so, data augmentation has long been in the toolbox of any neural-net designer and frameworks such as Keras often provide easy augmentation APIs. Unfortunately, these frameworks run into all of the above problems. Modern regularization techniques such as dropout can also help train CNNs on comparatively small datasets, but nothing replaces simply having more data with which to train.
]]>Robbie Ostrowrobbie@ostro.wsDo Basketball Referees Favor the Losing Team?2014-12-11T00:00:00+00:002014-12-11T00:00:00+00:00/foulsBasketball fans love a close game. A nail-biter with fifteen lead changes is much more fun to watch than a blowout.
But do the refs like close games as much as the rest of us?
Motivation to read on: they do.
The play-by-play data used in this analysis is curated by BasketballValue.com. You can find their files on this page. Alternatively, you can download the data in the final form that I used – regular-season data from 2006-2012 here, or the playoff data from 2007-2011 here.
All fouls with fewer than 3:00 minutes remaining were ignored, to minimize the impact of intentional fouls.
Only regular fouls were considered; technical fouls were ignored.
Home vs. Away
The first obvious task when collecting foul data is to examine the difference in the number of fouls recorded by the home and away teams. Here’s a histogram comparing them. Data above 0 means that there were more fouls called on the home team:
It looks pretty normal, with a mean just below 0 \((-.837)\). Sure, this is interesting, but it doesn’t reveal too much because differences in games with many fouls are weighted the same as differences in games with very few. Imagine a game in which the home team recorded 5 fouls and the visiting team 10. In this graph, it looks the same as a game in which the home team recorded 35 and the visiting team 40, though these games were fundamentally different. In the first, the away team had twice as many fouls; in the second, only 14% more. Thus, it’s more useful to look at a normalized measure.
This measure is expected “percentage difference” between the two foul categories, defined as 100 times the difference divided by the average, or \(200\times\frac{a-b}{a+b}\). For example, the percentage difference between 40 and 35 is \(13.33\%\).
Here is the same data graphed to reflect percentage difference rather than absolute difference:
Now that we have a normalized measure, we can find out whether the variation from zero is statistically significant. If we assume that the regular season data is a representative sample from the total pool of all NBA games, (it’s not, but such is life) we can determine a confidence interval for the real mean.
The mean percentage difference between the number of fouls recorded by the home team and the away team is \(-3.93\%\). A \(95\%\) confidence interval yields bounds between \(-4.57\%\) and \(-3.30\%\). The home team gets called for fewer fouls. This result is consistent with prior research; see this talk, presented at the Sloan conference at MIT, this paper examining NCAA basketball and coming to the same result, or this paper from the Journal of Economics and Management Strategy. The last paper also shows that the home team’s advantage rises as the number of fans increases, which suggests what Paul Aufiero (Patton Oswalt) was definitely thinking in Big Fan: refs favor the home team (at least in part) because of the crowd.
Winning vs. Losing
If refs want games to be close, we might expect that they (consciously or unconsciously) call more fouls on the team that’s currently in the lead.
Still ignoring the last three minutes of the game, this graph shows the percentage difference between fouls called on the team that is currently in the lead and the team that is currently losing. A number above 0 means that the leading team is more likely to get called for a foul.
This seems a little more biased.
Here, the mean percentage difference is \(6.91\%\), with a \(95\%\) confidence interval from \(6.20\%\) to \(7.63\%\)
Interestingly, despite the fact that the home team is less likely to foul and that the home team won almost \(60\%\) of their games during these seasons, the winning team at any given moment is more likely to record a foul. In fact, the percentage difference is almost \(7\%\). This is striking; make of it what you will.
Winning (by a lot) vs. Losing (by a lot)
If we make the same analysis, but only consider fouls that occurred when the point differential was 10 or more, we get the following graph (again, above 0 means the winning team fouled more):
There are peaks at \(\pm 200\%\) because many games only have one or two fouls when one team is winning by at least 10.
Now, the mean percentage difference is \(22.30\%\). Twenty-two percent!
This suggests one of two things:
The leading team is more likely to foul.
Referees are more likely to call fouls on the leading team.
This data can’t tell us why the winning team tends to foul more, but it seems unlikely that the winning team is actually more likely to commit a foul. Why would a team foul when they were 20 up – ever? It stops the clock, makes for easy points, (during bonus and for shooting fouls) etc. In fact, to me, it looks as though referees are very sympathetic to the losing team.
How Sympathetic?
If we vary the point differential that we examine, it’s clear that the greater the point differential, the more likely that a foul will be called on the leading team.
This graph is insane. It’s practically (within the error bars) increasing linearly. The greater the lead, the more likely that a foul will be called.
The same analysis on the playoff data yields the same trend, possibly even amplified. (We have less data, so the error is more severe.)
Conspiracy?
There’s a simple economic motivation to keep games close and exciting, but this data doesn’t offer any insight into whether the referees actually have that motivation in mind. Other studies suggest that teams facing elimination in the playoffs tend to be given an advantage by the refs, forcing each series to seven games as often as possible (and thus increasing revenues). However, I’m not comfortable saying that the NBA is encouraging this behavior by its referees; I imagine word would have gotten out by now. It’s probably just human nature. Nature that the NBA needs to fix!
There’s a lot more information to be teased out of this data. I’d love to hear any more results or insights.
]]>Robbie Ostrowrobbie@ostro.wsDemystifying Ghost2014-11-18T00:00:00+00:002014-11-18T00:00:00+00:00/ghostMy mother loves words. To this day, she insists that I should become a poet. During a road trip when I was little, she introduced me to a game called Ghost, and we would play all the time.
To play Ghost, players take turns choosing letters, creating a growing fragment of a word. The goal is to avoid completing a word while still maintaining the fragment’s property that it begins some word. There are two ways to lose a round: complete a word or fail to produce a word that begins with your fragment when challenged by an opponent. Of course, if the challenge is unsuccessful and you come up with a legitimate word, the challenger loses the round. Only words with more than three letters count. Generally, each player begins with five lives, one for each letter of G-H-O-S-T.
For example, imagine that Ada, Babbage, and Church are playing a friendly game of Ghost. Ada goes first and plays e. Babbage cleverly follows Ada’s e with an n of his own. Play continues: Church plays g, Ada plays i, and Babbage plays n. “Shucks,” Church says. I guess I’ll play e. Ada points and laughs and assigns Church a G for spelling “engine.” Simple enough.
Whenever I played with just my mom, she would start with the letter z. With only two players, it seemed as though there was no way to counter – she always won when she started with z. But luckily, instead of training to become a poet, I learned a little Python; now I’m the dominant Ghost player in the household.
Attention: If you plan to play Ghost with your friends, you should probably stop reading now so you don’t have a tiresome advantage.
When I initially solved Ghost to defeat my mother, I only looked into the two-player case. It turns out that Randall Munroe has, in his infinite wisdom, already solved Ghost for two players. In an effort not to be entirely redundant in this post, I’m sharing a solution here for n players. When Randall and I end up playing with a mysterious third party, he won’t know what hit him.
Enough talk. Let’s solve Ghost.
Pruning a Dictionary
First, we need a dictionary. The most reasonable one I could find is the american-english dictionary that ships with some versions of Ubuntu. (Find it at: https://packages.debian.org/wheezy/wamerican). I’m pretty sure this is the same dictionary Randall used.
You can use any dictionary you want, of course. I’m on OSX right now, so I also have Webster’s Second International built in: /usr/share/dict/web2. It has 234,936 words, most of which I don’t know. Some cursory googling also revealed TWL06, which seems to be a version of the American Scrabble dictionary.
Then, we prune this dictionary to contain only words that are lowercase (Proper Nouns Aren’t Allowed) and more than three letters long:
defis_legal_word(word,min_length):"""
returns True if the string `word` is longer than min_length
and consists entirely of lowercase letters.
"""returnlen(word)>=min_lengthandword.islower()defgen_word_list(dictionary,min_length):"""
returns a list of legal words parsed from a file where
each word is lowercase and seperated by a newline
character.
"""withopen(dictionary,'r')asw:words=[line.strip()forlineinwifis_legal_word(line.strip(),min_length)]returnwordswords=gen_word_list(DICTIONARY,4)len(words)
>>> 81995
Lists in Python are great, but they’re not the optimal structure for storing words (and – more importantly – prefixes of words) in this case. Enter the trie (from retrieval). A trie is an ordered tree in which every descendant of a node shares the same prefix. A picture would probably be useful; in the diagram below, each complete word is labeled with an arbitrary numeric key. From Wikimedia commons:
Tries are pretty memory efficient too – as you can see in the figure above, we’re storing 8 words using 11 nodes. Finding if a specific word is in a trie is trivially \(O(l)\) where \(l\) is the length of the word, because all you need to do is spell the word to find it. In an unsorted list, such an operation is \(O(n)\), and it’s \(O(log(n))\) using binary search on a sorted list, where \(n\) is the size of the corpus. Finding common prefixes and similar operations is equivalently easy. We won’t implement a trie or get into the nitty-gritty details – that might be a topic for another day. Luckily, there are already a few implementations of Python tries available. This solution uses datrie.
The first thing to do is make the trie from the corpus we just loaded into memory:
importdatrieimportstringdefmake_trie_from_word_list(word_list):"""
given a list of lowercase words, constructs a trie
with `None` as each value.
"""trie=datrie.Trie(string.ascii_lowercase)forwordinword_list:trie[word]=Nonereturntrieorig_trie=make_trie_from_word_list(words)
Notice that we’re never going to use a word that has a prefix that is another word. We’ll never get to “rainbow” because somebody will have already lost on “rain.” Let’s prune the trie to contain only words that don’t have legal words as prefixes:
# We'll actually create a whole new trie, because deleting from
# a trie is unpleasant.
defprune_trie(trie):"""
Given a lowercase datrie.Trie, returns a new trie in which no word
has any prefixes that are also legal words.
"""prefixless=[wordforwordintrie.keys()iflen(trie.prefixes(word))==1]returnmake_trie_from_word_list(prefixless)trie=prune_trie(orig_trie)len(trie)
>>> 19631
Now we’re in prime Ghost-solving territory.
Solving Ghost
To solve Ghost means to find out which players can lose from every possible game state, assuming all players play perfectly.
We’ll store this solution in another trie, where the keys are every substring in the original trie and the values are sets with the possible losers from that node.
The Algorithm
We could solve this with some clever recursion, but it’s easier to take advantage of the structure of the trie. To determine the losers in every possible game state, we perform a level-order traversal of the trie and follow these rules at every node:
If the node is a leaf node, then it completes a word. In that case, the loser is get_turn(word_length, num_players) where word_length is equal to the depth of the trie at the leaf node.
If the node is not a leaf node:
If all of the node’s children include the current player in the set of losers, then the player is indifferent between options because any move is a losing move. In that case, the set of losers at the current node is the union over all of the children’s losers.
If there is at least one child whose set of losers does not include the current player, then the current player does not lose and is indifferent between all non-losing options. In that case, the set of losers at the current node is the union over all of the sets of children’s losers that do not include the current player.
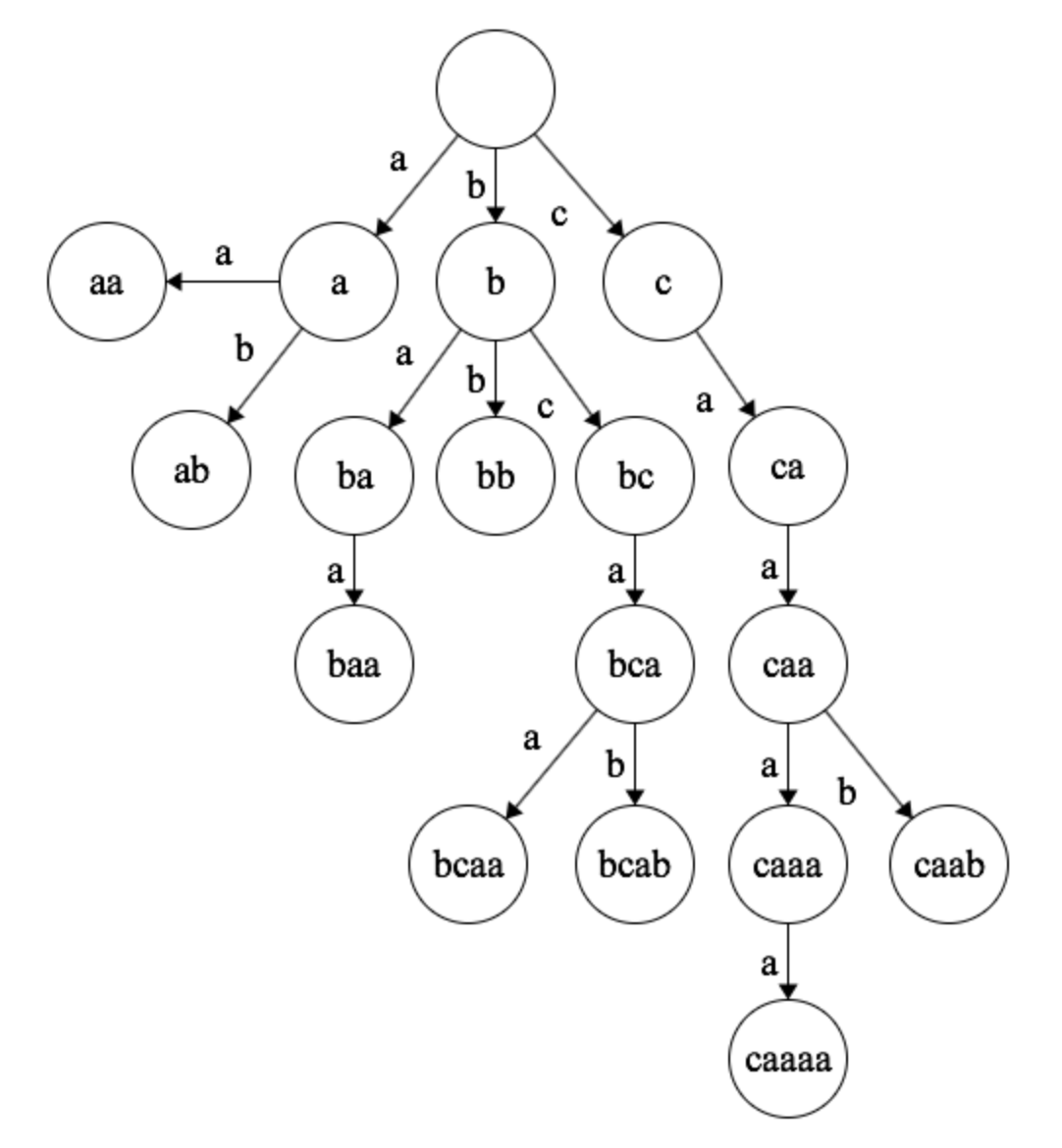
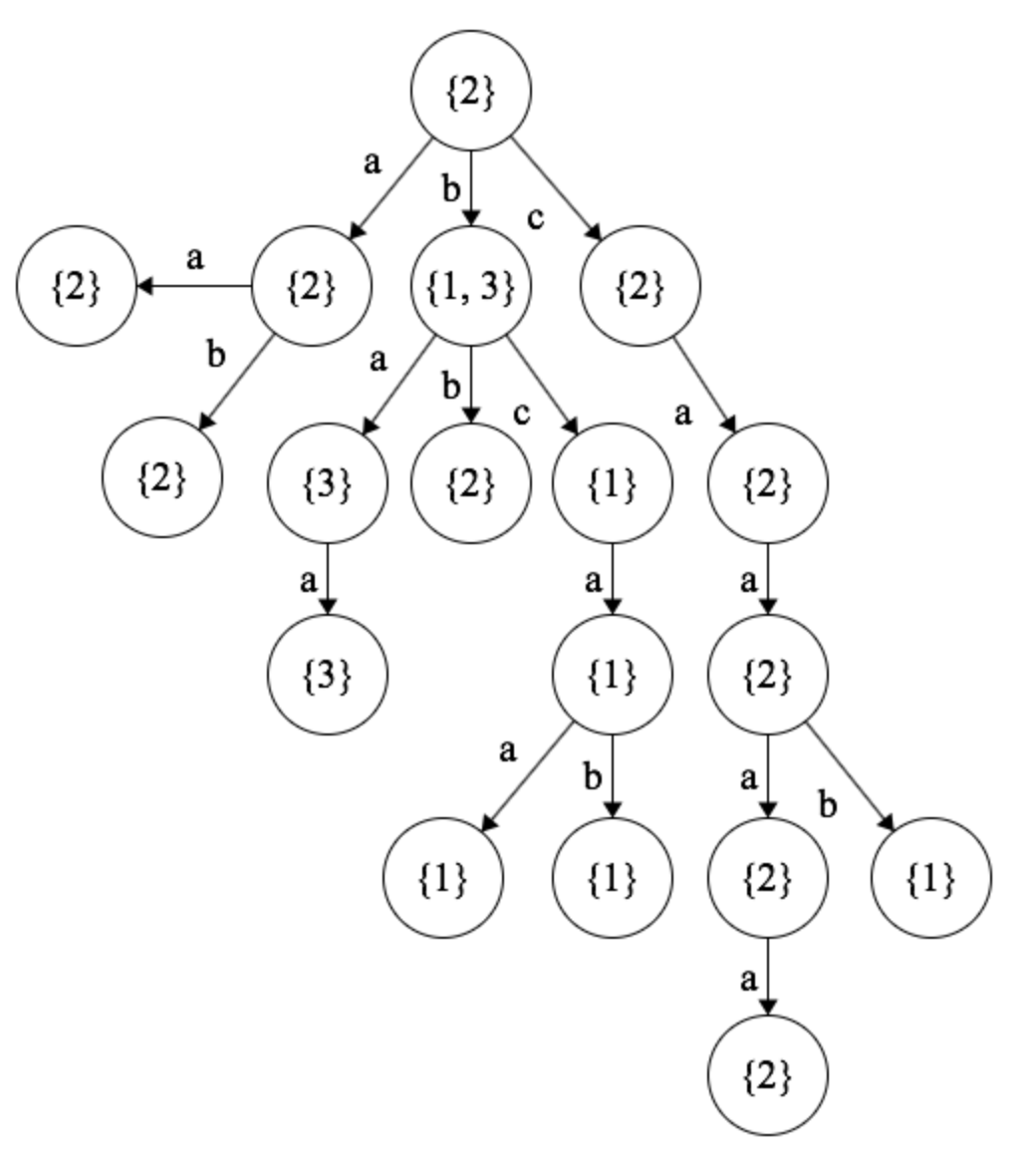
For an example, consider a trie with the words “aa”, “ab”, “baa”, “bb”, “bcaa”, “bcab”, “caaaa”, and “caab”:
If we follow the algorithm above, then it’s easy to derive the losers at each node:
As you can see, player 2 loses. Player 1 will play either ‘a’ or ‘c,’ forcing player 2 into a losing situation. Even though player 1 is not guaranteed to lose with a move of ‘b,’ it counts as a losing node because the other players can coordinate to make player 1 lose.
Finally, it’s time for the actual implementation. Instead of doing a formal level-order traversal, we’re just examining substrings from longest to shortest (ordered arbitrarily within those equivalence classes). This works because once we have solved for all strings of length \(n\), we can solve for all strings of length \(n-1\).
Before we get ahead of ourselves, we need an easy way to find out whose turn it is at any node in the trie:
defget_turn(word_length,num_players):"""
Returns the id of the player who would finish a word
word_length letters long. Player ids are 1-indexed in
{1... num_players}.
"""return(word_length-1)%num_players+1print(get_turn(8,3))# 1231231**2**
print(get_turn(4,4))# 123**4**
print(get_turn(9,2))# 12121212**1**
>>> 2
>>> 4
>>> 1
# This function replaces a true level order traveral.
# We need it to specify the keys in our solution trie.
defget_all_substrings(trie):"""
Parameters:
trie: a datrie.Trie
Returns: a list of all possible substrings of
words in the trie, sorted by length from
longest to shortest.
"""substrings=set([''])forwordintrie.keys():substrings.update([word[:p]forpinrange(1,len(word))])substrings=list(substrings)substrings.sort(key=len,reverse=True)returnsubstrings# This is the "meat" of the algorithm that's discussed in the bullets above.
defget_losers(solution,substring,turn):"""
Parameters:
solution: a datrie.Trie containing the working solution
(must be solved for all substrings longer than substring)
substring: the current position in the trie
turn: the current player
Returns: the set of losers from the node reached by spelling `substring`
"""# Lists the losers of all of the immediate children
next_losers=[bfora,binsolution.items(substring)iflen(a)==len(substring)+1]curr_player_loss=set()other_player_loss=set()curr_player_loses=Trueforloserinnext_losers:ifcurr_player_losesandturninloser:# So far, the current player loses no matter what,
# so the player is indifferent between all losing
# situations.
curr_player_loss|=loserelifturnnotinloser:# indifferent between all winning situations.
other_player_loss|=losercurr_player_loses=Falseifcurr_player_loses:returncurr_player_lossreturnother_player_lossdefsolve(trie,num_players):"""
Parameters:
trie: a datrie.Trie, pruned such that there are no
words that have prefixes that are also words
num_players:
the number of players for which to solve
Returns: a 2-tuple (solution, num_players) where `solution`
is a datrie.Trie where every node stores the losing set in its
value. num_players is just along for the ride.
"""solution_trie=datrie.Trie(string.ascii_lowercase)substrings=get_all_substrings(trie)forwordintrie.keys():# base case: complete words
loser=get_turn(len(word),num_players)solution_trie[word]=set([loser])forsubstringinsubstrings:# once we have solved for every leaf node, we
# can work our way up the trie.
turn=get_turn(len(substring)+1,num_players)solution_trie[substring]=get_losers(solution_trie,substring,turn)returnsolution_trie,num_players
Let’s find out who loses from each initial position in a 2-player game.
'' {2}
a {1}
b {1}
c {1}
d {1}
e {1}
f {1}
g {1}
h {2}
i {1}
j {2}
k {1}
l {1}
m {2}
n {1}
o {1}
p {1}
q {1}
r {2}
s {1}
t {1}
u {1}
v {1}
w {1}
x {1}
y {1}
z {2}
There, Ghost is solved! solution[prefix] gives a set of losers from that prefix. Any self-respecting game theorist would stop now, but I’m neither of those things. It’s no fun to only know who loses with optimal play – it’s a lot better to actually know how to play optimally in any non-doomed situation. This function takes the solution we just computed, along with the current state of the game (some prefix to a word) and returns the winning moves for the current player.
deflist_winning_moves(solution,current_state):"""
Parameters:
solution: the 2-tuple returned from solve
current_state: the incomplete word that has been spelled
so far
Returns: a set of winning moves for the current player. The
empty set if there are no winning moves.
"""player=get_turn(len(current_state)+1,solution[1])winning_moves=set()ifplayerinsolution[0][current_state]:# player loses, return empty set
returnwinning_movespaths=[(a,b)fora,binsolution[0].items(current_state)iflen(a)==len(current_state)+1]forword,losersinpaths:ifplayernotinlosers:winning_moves.update(word[-1])returnwinning_movessolution=(solution_trie,num_players)print(list_winning_moves(solution,''))print(list_winning_moves(solution,'h'))print(list_winning_moves(solution,'b'))
If you arbitrarily choose a letter from the above function, you have an infallible Ghost AI.
Minimal Strategies
Because it would be nearly impossible to memorize optimal moves from every game state, the last task is to find a minimal list of winning words. Some dictionaries have many such lists – this function finds an arbitrary one. First, let’s just find the list of all “winning words,” or those that can be reached without going into a losing state (we’ll store these in a trie again):
deflist_winning_words(trie,solution,current_state):"""
Parameters:
trie: The pruned trie initialized from the dictionary
solution: the 2-tuple returned from solve
current_state: the incomplete word that has been spelled
so far
Returns: the set of winning words for the current player. The
empty set if there are no winning moves.
"""current_player=get_turn(len(current_state)+1,solution[1])winning_words=set(trie.keys(current_state))forwordintrie.keys(current_state):forsubstrin(word[:p]forpinrange(len(current_state),len(word))):# If the current player can lose on the way to the winning word,
# it is not a "winning word"
ifcurrent_playerinsolution[0][substr]:winning_words-=set([word])continuereturnmake_trie_from_word_list(list(winning_words))winning_trie=list_winning_words(trie,solution,'')
To minimize, we recursively examine the size of the winning set that each possible set of moves would create. This is a slow approach with no pruning, but the winning sets at this point are relatively small so it’s not too much of a concern.
defminimize_strategy(winning_trie,solution,current_state):"""
Parameters:
winning_trie: a trie initialized from the output of list_winning_words
with the same current_state
solution: the 2-tuple returned from solve
current_state: the incomplete word that has been spelled
so far
Returns: the minimal set of winning words for the current player, assuming.
all players play perfectly. The empty set if there are no winning moves.
"""ifcurrent_stateinwinning_trie:returnset([current_state])possible_moves=list_winning_moves(solution,current_state)num_players=solution[1]best_move=Noneformoveinpossible_moves:this_move=set()state=current_state+moveforwordinwinning_trie.keys(state):this_move.update(minimize_strategy(winning_trie,solution,word[:len(current_state)+num_players]))ifnotbest_moveorlen(best_move)>len(this_move):best_move=this_movereturnbest_moveminimize_strategy(winning_trie,solution,'')
Player 1's minimal strategy:
: {'juvenile', 'jail', 'jilt', 'jowl', 'jejune'}
Player 2's minimal strategy:
a : {'aorta'}
b : {'blimp', 'blemish', 'bloat', 'black', 'blubber'}
c : {'crack', 'crepe', 'crick', 'crozier', 'crypt', 'crept', 'crucial'}
d : {'djinn'}
e : {'ejaculate', 'ejaculation', 'eject'}
f : {'fjord'}
g : {'gherkin', 'ghastliness', 'ghastly', 'ghoul'}
h : No winning moves.
i : {'iffiest'}
j : No winning moves.
k : {'khaki'}
l : {'llama'}
m : No winning moves.
n : {'nymph', 'nylon'}
o : {'ozone'}
p : {'pneumatic'}
q : {'quoit', 'quack', 'quest', 'quibble', 'quibbling'}
r : No winning moves.
s : {'squeeze', 'squelch', 'squeamish', 'squeezing'}
t : {'trochee', 'truffle', 'tryst', 'traffic', 'triumvirate', 'trefoil'}
u : {'uvula'}
v : {'vulva'}
w : {'wrath', 'wrought', 'wrist', 'wrung', 'wryly', 'wreck'}
x : {'xylem'}
y : {'yttrium'}
z : No winning moves.
3+ Players
Below is the minimal strategy for three players. It’s a little unwieldy to memorize, though.
The minimal strategy for 3+ players isn’t particularly useful in a real game, however, because it assumes that all players play perfectly. It’s possible that one of the other 2+ players won’t play in his/her/its own best interest, so the final word could end up being outside any winning strategy.
Interestingly, it’s possible for all 3+ players to be in a losing situation in the same context. Since no player knows what the others will do if indifferent between options, some prefix could be equally “dangerous” for all players.
get_minimal_strategies(DICTIONARY,3,4)
Player 1's minimal strategy:
: {'quorum', 'quixotic', 'quest', 'quatrain'}
Player 2's minimal strategy:
a : {'ajar'}
b : {'byes', 'bypass', 'byplay', 'bystander', 'byelaw', 'byproduct', 'byte', 'bygone', 'bypast'}
c : {'czar'}
d : No winning moves.
e : {'eons'}
f : No winning moves.
g : {'gaff', 'gaps', 'gavotte', 'gage', 'gander', 'gantlet', 'gawk', 'gaping', 'gather', 'gave', 'gape', 'gating', 'gang', 'gags', 'gagged', 'gate', 'gannet', 'gaging'}
h : No winning moves.
i : {'iamb'}
j : No winning moves.
k : {'krypton', 'kronor'}
l : No winning moves.
m : {'myna', 'myopia', 'myth', 'myself', 'myopic', 'mysteries', 'mystery'}
n : No winning moves.
o : {'oyster'}
p : {'pneumonia', 'pneumatic'}
q : No winning moves.
r : No winning moves.
s : {'svelte'}
t : {'tzar'}
u : {'ubiquitous'}
v : No winning moves.
w : {'wuss'}
x : No winning moves.
y : {'yttrium'}
z : {'zygote'}
Player 3's minimal strategy:
ab : {'abhor'}
ac : {'acme'}
ad : {'adze'}
ae : {'aegis'}
af : {'afar'}
ag : {'ague'}
ah : {'ahoy'}
ai : {'aisle'}
aj : {'ajar'}
ak : No winning moves.
al : {'alum'}
am : {'amnesia', 'amniocenteses'}
an : {'anus'}
ao : {'aorta'}
ap : {'apse'}
aq : {'aquiline', 'aquiculture', 'aqueous', 'aqueduct', 'aquifer', 'aqua'}
ar : {'arks'}
as : {'asocial'}
at : {'atelier'}
au : {'auxiliaries'}
av : {'avow', 'avoirdupois', 'avocado', 'avoid'}
aw : {'awry'}
ax : {'axon'}
ay : {'ayes'}
az : {'azure'}
ba : {'baffling'}
be : {'bebop'}
bi : {'bizarre'}
bl : {'blow', 'bloc', 'blooper', 'blond', 'bloom', 'blog', 'blossom', 'blood', 'blob', 'bloat', 'blousing', 'blot'}
bo : {'bozo'}
br : {'bras', 'bravado', 'brackish', 'bravo', 'bran', 'brawl', 'brawn', 'bracing', 'brace', 'brag', 'bramble', 'bravura', 'brave', 'brain', 'braising', 'brat', 'braille', 'braving', 'bray', 'braking', 'brad', 'braid', 'bract', 'brake'}
bu : {'buzz'}
by : {'byte'}
ca : {'cayenne'}
ce : {'cephalic'}
ch : {'chlorophyll'}
ci : {'cistern'}
cl : No winning moves.
co : {'cove'}
cr : No winning moves.
cu : {'cuff'}
cy : {'cyanide'}
cz : {'czar'}
da : {'dawdling', 'dawn'}
de : {'demo', 'demur'}
dh : {'dhoti'}
di : {'dibbling'}
dj : {'djinn'}
do : {'doff'}
dr : {'drub', 'drunk', 'drug', 'drudging', 'druid', 'drum'}
du : {'duff'}
dw : {'dwarves', 'dwarf'}
dy : {'dyke'}
ea : {'eave'}
eb : {'ebullience'}
ec : {'ecumenical'}
ed : {'educable'}
ef : No winning moves.
eg : {'egalitarian'}
ei : {'eider'}
ej : {'eject'}
ek : {'eking'}
el : {'elms'}
em : {'emcee'}
en : {'envelop', 'envy', 'envoy'}
eo : {'eons'}
ep : {'epaulet'}
eq : {'equinoctial', 'equestrian', 'equability', 'equilateral', 'equip', 'equivalent', 'equal', 'equidistant', 'equator', 'equities', 'equivalence', 'equinox', 'equanimity'}
er : {'erect'}
es : {'esquire'}
et : {'eternal'}
eu : {'eucalyptus'}
ev : {'ever', 'eves', 'even'}
ew : {'ewer', 'ewes'}
ex : {'exult', 'exude', 'exuberance', 'exuding'}
ey : {'eyrie'}
fa : {'favor'}
fe : {'fever'}
fi : {'five'}
fj : {'fjord'}
fl : {'flea', 'flex', 'fleck', 'fled', 'flee', 'flesh', 'flew'}
fo : {'foyer'}
fr : No winning moves.
fu : {'fuel'}
ga : {'gaff'}
ge : {'gear'}
gh : {'ghoul', 'ghost'}
gi : {'gift'}
gl : {'glee', 'glean', 'glen', 'gleam'}
gn : {'gnus'}
go : {'gown'}
gr : {'gryphon'}
gu : {'guzzling'}
gy : {'gyrating', 'gyration', 'gyro'}
ha : {'haemophilia'}
he : {'heft'}
hi : {'hims'}
ho : {'hock'}
hu : {'huff'}
hy : {'hyena'}
ia : {'iamb'}
ib : {'ibex'}
ic : {'icon'}
id : {'idyl'}
if : {'iffiest', 'iffy'}
ig : {'igloo'}
ik : {'ikon'}
il : {'ilks'}
im : No winning moves.
in : {'inquietude', 'inquest'}
io : {'iota'}
ip : No winning moves.
ir : {'iron'}
is : {'isms'}
it : {'itch'}
iv : {'ivies'}
ja : {'jazz'}
je : {'jewel'}
ji : {'jiujitsu'}
jo : {'jowl'}
ju : {'just'}
ka : {'kazoo'}
ke : {'kestrel'}
kh : {'khaki', 'khan'}
ki : {'kiwi'}
kl : {'klutz'}
kn : {'knavish', 'knave', 'knapsack', 'knack'}
ko : {'koala'}
kr : {'krypton'}
ku : {'kumquat'}
la : {'lallygag'}
le : {'left'}
li : {'lion'}
lo : {'lozenge'}
lu : {'luau'}
ly : {'lymph'}
ma : {'maxed', 'maxes'}
me : {'meow'}
mi : {'miff'}
mn : {'mnemonic'}
mo : {'mozzarella'}
mu : {'muzzling'}
my : {'myth'}
na : {'nays'}
ne : {'need'}
ni : {'nirvana'}
no : {'noxious'}
nu : {'nuzzling'}
ny : {'nymph'}
oa : {'oasis', 'oases'}
ob : {'obit'}
oc : {'ocarina'}
od : {'odes'}
of : {'often'}
og : {'ogre'}
oh : {'ohms'}
oi : {'oink', 'ointment'}
ok : {'okay'}
ol : {'olfactories'}
om : {'ominous', 'omit', 'omission'}
on : {'onion'}
op : {'opossum'}
or : {'orotund'}
os : {'osier'}
ot : {'other'}
ou : {'ours'}
ov : {'ovoid'}
ow : {'owing'}
ox : {'oxbow'}
oy : No winning moves.
oz : {'ozone'}
pa : {'paean'}
pe : {'pejorative'}
ph : {'phrasal', 'phrenology'}
pi : {'pirouetting'}
pl : No winning moves.
pn : No winning moves.
po : {'poxes'}
pr : No winning moves.
ps : {'psalm'}
pt : {'pterodactyl'}
pu : {'puzzling'}
py : {'pyorrhea'}
qu : No winning moves.
ra : {'raja'}
re : {'request', 'requiem'}
rh : {'rhubarb'}
ri : {'riot'}
ro : {'royal'}
ru : {'ruff'}
sa : {'sahib'}
sc : {'scything'}
se : {'sever', 'seven'}
sh : No winning moves.
si : {'sift'}
sk : {'skating', 'skate'}
sl : No winning moves.
sm : {'smear', 'smelt', 'smell'}
sn : {'sneezing', 'sneer', 'sneak'}
so : {'sojourn'}
sp : {'sphinges', 'spheroid'}
sq : No winning moves.
st : No winning moves.
su : {'suturing'}
sv : No winning moves.
sw : {'swum', 'swung'}
sy : No winning moves.
ta : {'tadpole', 'tads'}
te : {'tequila'}
th : {'thalamus', 'that', 'thallium', 'thaw', 'than', 'thalami'}
ti : {'tiff'}
to : {'toque'}
tr : No winning moves.
ts : {'tsar'}
tu : {'tuft'}
tw : No winning moves.
ty : {'tyke'}
tz : {'tzar'}
ub : {'ubiquitous', 'ubiquity'}
ud : {'udder'}
ug : {'ugliness', 'ugliest', 'ugly'}
uk : {'ukulele'}
ul : {'ulcer'}
um : {'umiak'}
un : {'unzip'}
up : {'upend'}
ur : {'uranium'}
us : {'using'}
ut : {'utter'}
uv : {'uvula'}
va : {'vain'}
ve : {'veal'}
vi : {'vixen'}
vo : {'vouch'}
vu : No winning moves.
vy : {'vying'}
wa : {'waffling', 'wafer', 'waft'}
we : {'were'}
wh : {'whys'}
wi : {'wife'}
wo : {'wove'}
wr : {'wrung'}
wu : {'wuss'}
xe : {'xerography', 'xerographic'}
xy : {'xylophonist', 'xylem'}
ya : {'yank'}
ye : {'yews'}
yi : {'yield'}
yo : {'yore'}
yt : {'yttrium'}
yu : {'yule'}
za : No winning moves.
ze : {'zero'}
zi : {'zilch', 'zillion'}
zo : {'zombi'}
zu : {'zucchini'}
zw : {'zwieback'}
zy : No winning moves.
Losers
It is of the utmost importance to decide on a dictionary before partaking in a friendly game of Ghost. Player 2 can win using the Scrabble dictionary, but player 1 always wins with the other two.
Dictionary
Minimum Word Length
Number of players
Losers
Winning moves for player 1
web2
3
2
{2}
{‘a’, ‘h’, ‘l’}
web2
3
3
{3}
{‘t’, ‘a’, ‘d’, ‘n’}
web2
3
4
{3, 4}
{‘j’, ‘l’}
web2
4
2
{2}
{‘a’, ‘h’, ‘l’, ‘e’}
web2
4
3
{3}
{‘t’, ‘a’, ‘d’}
web2
4
4
{3, 4}
{‘j’, ‘r’, ‘l’}
TWL06
3
2
{1}
None
TWL06
3
3
{3}
{‘m’, ‘n’}
TWL06
3
4
{3, 4}
{‘h’, ‘q’}
TWL06
4
2
{2}
{‘m’, ‘n’}
TWL06
4
3
{1,2,3}
None
TWL06
4
4
{3, 4}
{‘h’, ‘q’}
american-english
3
2
{2}
{‘j’, ‘m’, ‘h’, ‘z’}
american-english
3
3
{2, 3}
{‘n’, ‘s’, ‘q’, ‘r’, ‘z’, ‘p’}
american-english
3
4
{3, 4}
{‘r’, ‘z’}
american-english
4
2
{2}
{‘j’, ‘m’, ‘h’, ‘r’, ‘z’}
american-english
4
3
{2, 3}
{‘s’, ‘p’, ‘q’}
american-english
4
4
{4}
{‘m’, ‘z’}
The Moral: if you’re going to play Ghost with your mother, make sure you use the Scrabble dictionary. Then you can win when she plays ‘z.’
Download
To experiment yourself, you can download this post as an iPython notebook. However, I’ve also implemented a more flexible “Ghost” class that you can download here along with a basic test suite here.
As always, any suggestions, corrections, criticisms (constructive or otherwise), and witticisms welcome.